
AWS Elasticsearch Maximum Shards Per Index
The intent of this post is to help answer the question: How many shards per index can a multi-az/zone-aware AWS Elasticsearch with ‘routing.allocation.total_shards_per_node’ enabled handle? Heck of a question, I’m not sure of another way to phrase that as a one-liner…
As you may already know visiting this post, with the elasticsearch index setting ‘routing.allocation.total_shards_per_node’, assigning more shards than can be routed in the cluster will result in an index going yellow (replica shards can’t be allocated) or even red (if primary shards can’t be allocated).
Background: I use AWS ES as the E in an ELK stack. My log indices can get REALLY busy and since AWS ES severly limits options on manually routing/balancing shards, using ‘routing.allocation.total_shards_per_node’ is one way I can distribute R/W load among the nodes of the cluster. I also operate this cluster AZ aware across 3 AZs, so AWS ES auto-configures zone/shard awareness and I’ve yet to find a good white paper on how AWS ES specifically implements this shard awareness in opendistro this is about as good as I’ve found.
Problem: In a multi-AZ AWS ES cluster, what is the maximum number of shards I can request in an index and have AWS allocate them appropriately?
This deserves some testing…
Goal: Create a repeatable formula that tells me exactly how many shards I can request from a multi-az aware ES cluster.
Approach: Create real multi-AZ zone aware clusters, and with an index setting of ‘routing.allocation.total_shards_per_node: 1’, create indices with more and more shards until an index when yellow. At that point, I know with a cluster of size X, an index can have Y - 1 shards and allocate primary and replicas just fine.
Here’s an example CURL to create an index
curl --request PUT 'http://<yourclusteraddresshere>:<port>/index-foo' \
--header 'Content-Type: application/json' \
--data-raw '
{
"settings" : {
"index" : {
"number_of_shards" : 5,
"routing.allocation.total_shards_per_node": 1,
"number_of_replicas" : 1
}
}
}
'Time to break out the spreadsheet…
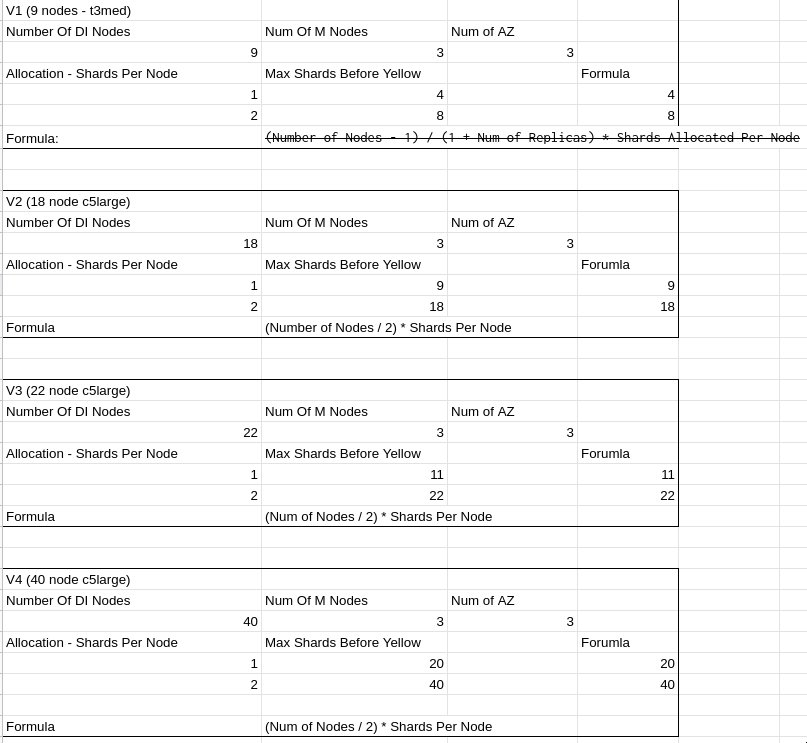
First attempt I went a little off the deep end with my theory… It didn’t hold up on trial 2 but a new formula was derived which did!
Result:
(Number of Nodes / 2) * Shards Per Node
# Or what I assume actually is...
(Number of Nodes / (1 primary shard + N replica shards)) * Shards Per NodeSo given a cluster of 40 nodes, I could request a maximum of 20 shards before the index went yellow. Please note that increasing shards adds additional lucine indices for ES to keep track of, and there’s a balancing point I won’t get into regarding optimal & consistent sizes for ALL indices in your cluster.
Documentation dump: